在Centos7系统上进行安装,采用hadoop2.7.1
下载相关软件
hadoop下载:
http://hadoop.apache.org/releases.html
官网上提供的是hadoop源码包和32位安装包,我的centos7是64位,所以找了一个别人用源码在Centos7上编译好的安装包。也可以自己下载源码编译。
jdk1.8下载:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
准备工作
配置机器
搭建三个机器为例:node-1、node-2、node-3
- node-1:\<NameNode> [ResourceManager]
- node-2:\<DataNode> \<SecondaryNameNode> [NodeManager]
- node-3:\<DataNode> [NodeManager]
修改机器名称
1 | # 注意,centos7以下版本是直接修改/etc/network文件 |
设置主机名映射
将主机名和ip地址映射起来,在三台机器中都配置
1 | vim /etc/hosts |
1 | 172.16.199.129 node-1 |
配置三台机器ssh免密码登录
- 在node-1中生成密匙(私匙id_ras、公匙id_rsa.pub):ssh-keygen -t rsa
- 将公匙id_rsa.pub拷贝到要进行ssh登录的机器上:ssh-copy-id -id <机器名称>
1 | #在node-1中: |
关闭防火墙
1 | firewall-cmd --state #查看防火墙状态 |
安装jdk1.8
hadoop是依赖于jdk环境的
在hadoop中可以看到有很多jar包,所以hadoop的启动必须有jdk环境
配置好jdk环境变量
1 | export JAVA_HOME=/usr/local/program/java/jdk1.8.0_171 |
安装hadoop
下载hadoop64位安装包,我下载的是hadoop-2.7.1-cent0s7-64.tar.gz
放在三个服务器下,解压
1 | # 解压后文件:hadoop-2.7.1 |
hadoop相关配置
在node-1机器上进行配置
修改配置文件
进入hadoop-2.7.1的配置目录:hadoop-2.7.1/hadoop-2.7.1/etc/hadoop
hadoop的配置文件有两种,
- *-default.xml:配置了hadoop的默认配置
- *-site.xml:配置用户自定义的配置选项
如果用户想自定义一些属性变量配置,就进入*-site.xml配置,配置之后会覆盖默认配置文件的相应配置;如果没有配置其他的配置选项,则会启动*-default.xml的配置
修改hadoop-env.sh
修改自己安装的的jdk路径,hadoop启动时加载jdk:
1 | # export JAVA_HOME=${JAVA_HOME} |
修改hadoop核心配置文件:core-site.xml
在core-site.xml文件的下
1 | <configuration> |
修改hdfs-site.xml
DFS namenode存放配置:
1 | <configuration> |
修改mapred-site.xml
mapreduce相关配置,job监控地址和端口等配置文件
修改文件名称
1 | mv mapred-site.xml.template mapred-site.xml |
1 | <configuration> |
修改yarn-site.xml
1 | <configuration> |
修改slaves
删除文件内容localhost,指定机器:
1 | node-1 |
配置hadoop环境变量
将环境变量配置到/etc/profile文件中:
1 | export HADOOP_HOME=/usr/local/program/server/hadoop-2.7.1 |
修改文件后重新加载文件:
1 | source /etc/profile |
全部配置
将以上所有修改发送到另外两台机器上(node-2,node-3)
1 | scp -r /usr/local/program/server/hadoop-2.7.1/ root@node-2:/usr/local/program/server/ |
在node-2,node-3两台机器上分别重新加载/etc/profile文件
hadoop启动
hadoop启动,必须要启动HDFS和YARN这两个集群
首次启动HDFS时,必须对他进行格式化
dhfs格式化
在启动hadoop集群之前,首先必须要进行一个初始化操作
格式化只能在初始启动之前启动一次,是对文件系统进行一些初始化操作,因为此时hdfs还不存在;在初始化完成之后,集群启动,之后不能再进行初始化
格式化是在hdfs集群的namenode上,也就是node-1机器
1 | hdfs namenode -format #或 hadoop namenode -format |
格式化完成之后,查看格式化过程中的日志,
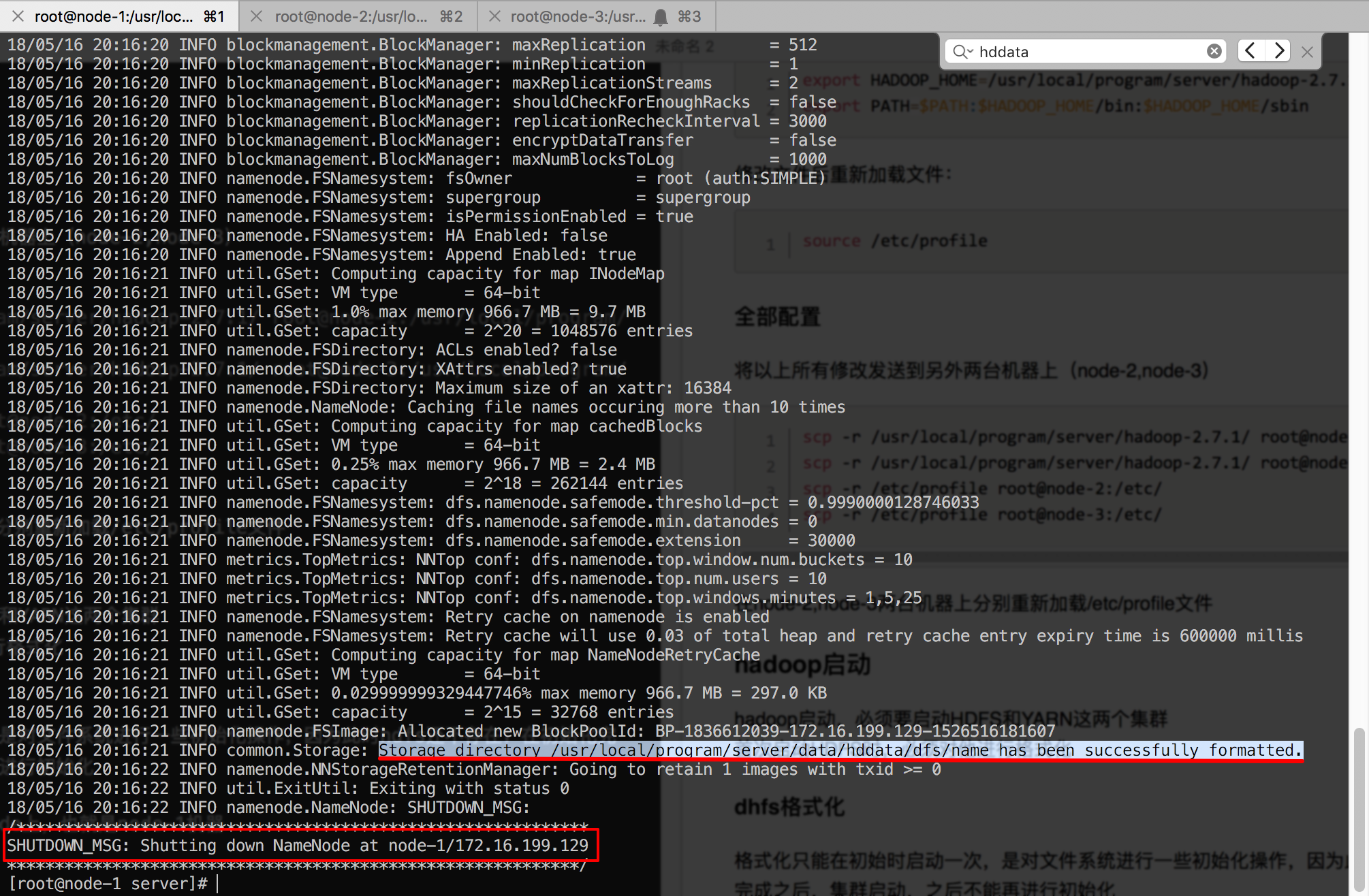
可以看到日志中创建了之前在core-site.xml配置中指定的文件目录
进入这个目录可以看到目录下生成的文件:(data/hddata/dfs/name/current/下)
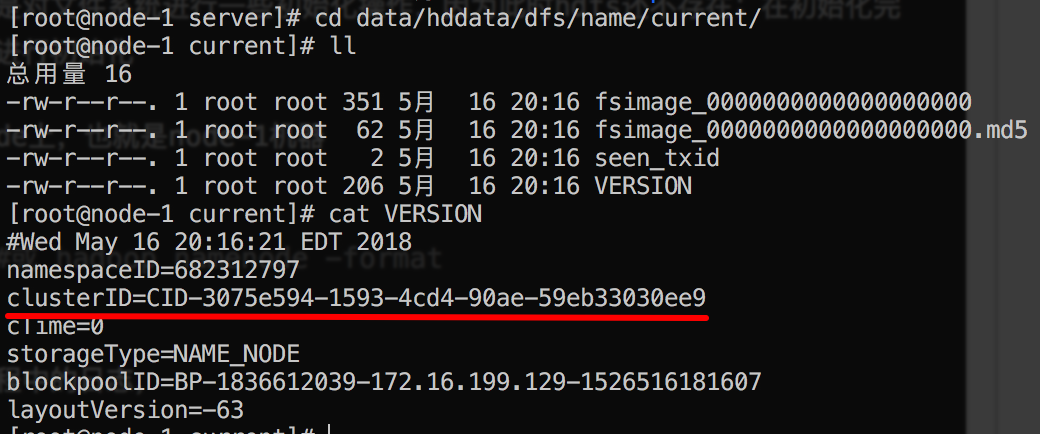
在VERSION中有一个clusterID,这个值是每一次hdfs初始化时产生的一个值,一旦重新初始化,这个值就会改变
启动hadoop集群
在namenode机器上启动(node-1)
方式一:共同启动所有节点
使用脚本,分别启动hdfs和yarn
前提:配置了hadoop-2.7.1/etc/hadoop/slaves文件和设置集群中机器的ssh免密登录
脚本在hadoop-2.7.1/sbin目录下
- hdfs:start-dfs.sh
- yarn:start-yarn.sh
方式二:单节点启动
分节点启动
1 | hadoop-daemon.sh start namenode |
使用jps查看启动节点
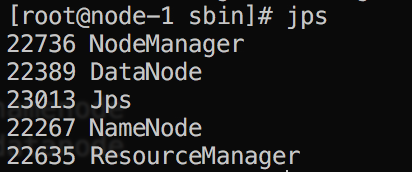
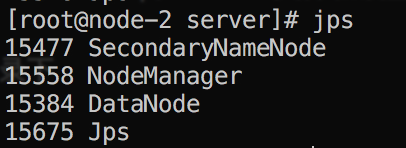
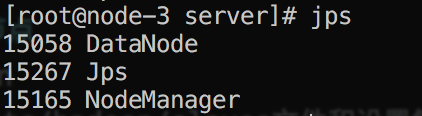
进入页面访问
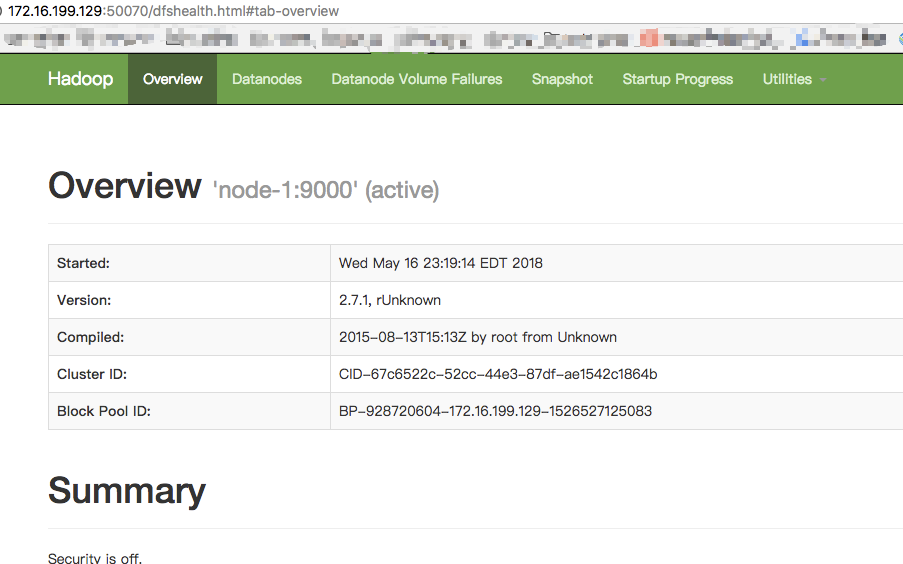
NameNode页面
访问NameNode页面配置,默认端口50070:
http://【你的NameNode所在机器ip】:50070/
测试dfs
在页面中查看文件系统

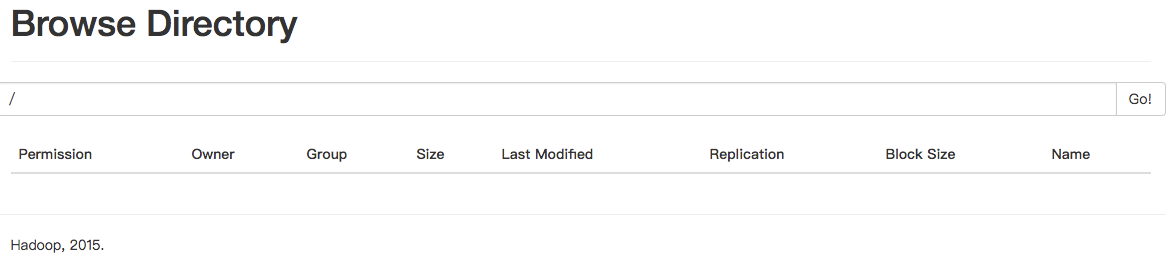
进入服务器查看:hdfs dfs -ls /
没有任何内容
在根目录下创建一个文件夹:hello_hadoop


ResourceManager页面
访问ResourceManager页面配置,默认端口8088:
http://【你的ResourceManager所在机器ip】:8088/
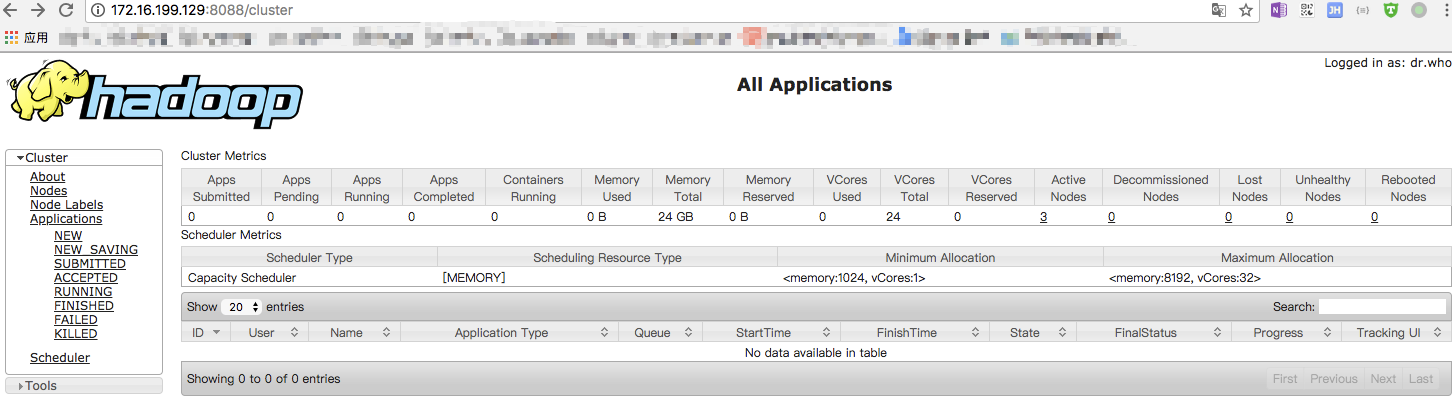
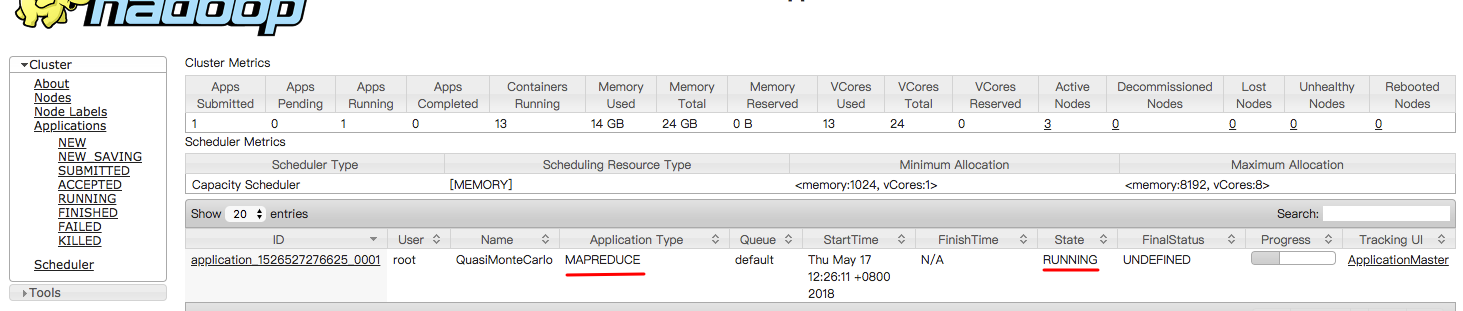
用官方示例运行mapreduce程序
在hadoop集群中任选一台机器
1 | cd hadoop-2.7.1/share/hadoop/mapreduce |